Summary
Pretrained language models, such as BERT and RoBERTa, have shown large improvements in the commonsense reasoning benchmark COPA. However, recent work found that many improvements in benchmarks of natural language understanding are not due to models learning the task, but due to their increasing ability to exploit superficial cues, such as tokens that occur more often in the correct answer than the wrong one. Are BERT's and RoBERTa's good performance on COPA also caused by this? We find superficial cues in COPA, as well as evidence that BERT exploits these cues. To remedy this problem, we introduce Balanced COPA an extension of COPA that does not suffer from easy-to-exploit single token cues. We analyze BERT's and RoBERTa's performance on original and Balanced COPA, finding that BERT relies on superficial cues when they are present, but still achieves comparable performance once they are made ineffective, suggesting that BERT learns the task to a certain degree when forced to. In contrast, RoBERTa does not appear to rely on superficial cues.
COPA: Choice of Plausible Alternatives
Given a premise, such as The man broke his toe, COPA requires choosing the more plausible, causally related alternative, in this case either: because He got a hole in his sock (wrong) or because He dropped a hammer on his foot (correct). To test whether COPA contains superficial cues, we conduct a dataset ablation in which we provide only partial input to the model.
Specifically, we provide only the two alternatives but not the premise, which makes solving the task impossible and hence should reduce the model to random performance. However, we observe that a model trained only on alternatives performs considerably better than random chance and trace this result to an unbalanced distribution of tokens between correct and wrong alternatives.
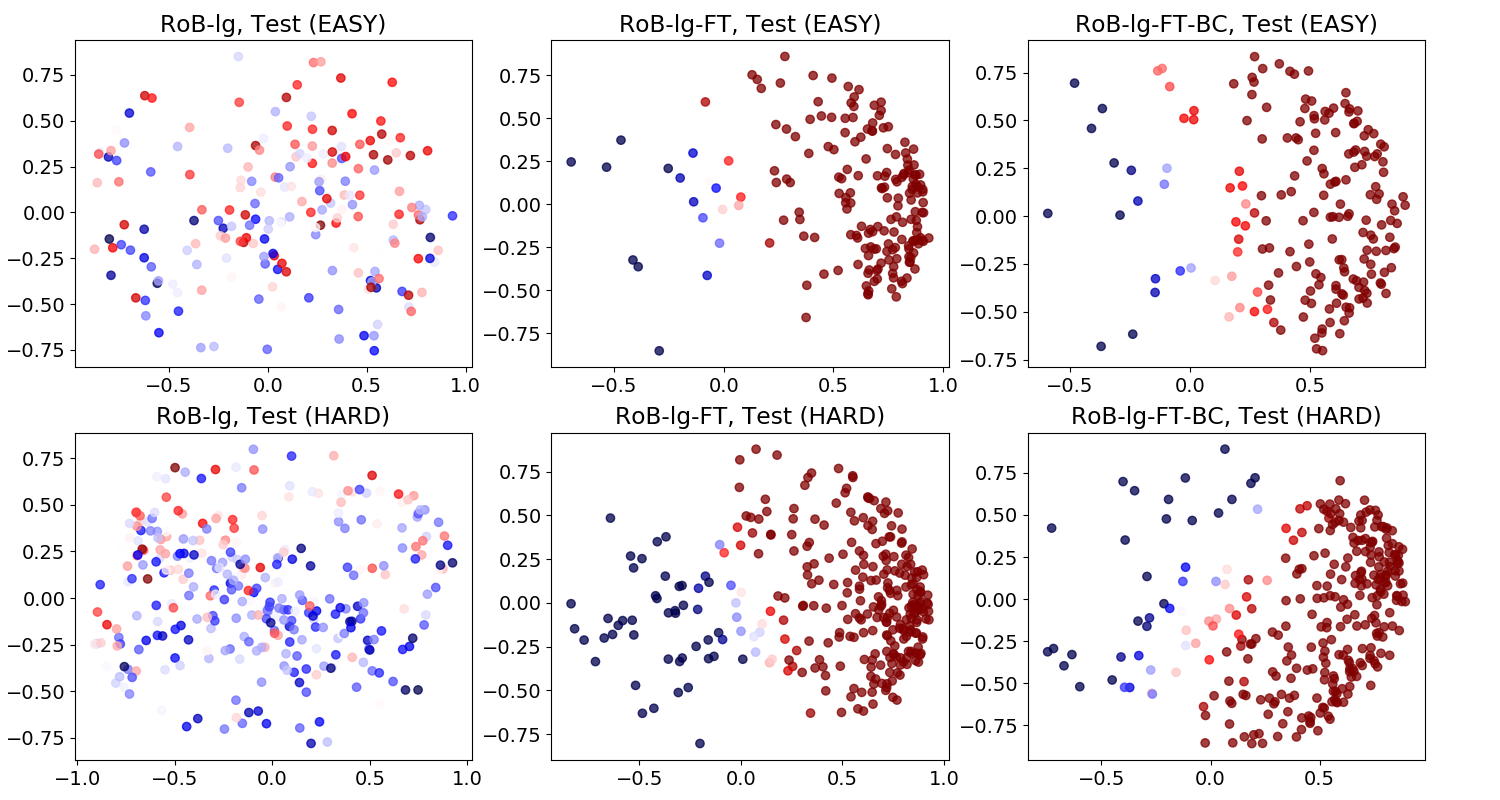
Further analysis reveals that finetuned BERT and RoBERTa perform very well on easy instances containing superficial cues, but worse on hard instances without such simple cues.
To prevent models from exploiting superficial cues in COPA, we introduce Balanced COPA
Balanced COPA

Balanced COPA contains one additional, mirrored instance for each original training instance. This mirrored instance uses the same alternatives as the corresponding original instance, but introduces a new premise which matches the wrong alternative of the original instance, e.g. The man hid his feet, for which the correct alternative is now because He got a hole in his sock. Since each alternative occurs exactly once as correct answer and exactly once as wrong answer in Balanced COPA, the lexical distribution between correct and wrong answers is perfectly balanced, i.e., superficial cues in the original alternatives have become uninformative.
Balanced COPA allows us to study the impact of the presence or absence of superficial cues on model performance. Download balanced_copa.tar.bz2 (27K)
Balanced COPA Examples
Original instance
The stain came out of the shirt. What was the CAUSE of this?
✔ I bleached the shirt.
✗ I patched the shirt.
Mirrored instance
The shirt did not have a hole anymore. What was the CAUSE of this?
✗ I bleached the shirt.
✔ I patched the shirt.
Original instance
The woman hummed to herself. What was the CAUSE for this?
✔ She was in a good mood.
✗ She was nervous.
Mirrored instance
The woman trembled. What was the CAUSE for this?
✗ She was in a good mood.
✔ She was nervous.
Superficial Cues (Annotation Artifacts)
One of the simplest types of superficial cues are unbalanced token distributions, i.e tokens appearing more often or less frequently with one particular instance label than with other labels. COPA contains single token cues, such as a, was, went, that are predictive of the correct alternative.
Easy/Hard Subsets
To investigate the behaviour of models trained on the original COPA, which contains superficial cues, we split the test set into an Easy subset and a Hard subset. The Easy subset consists of instances that are correctly solved by the premise-oblivious model, a model trained on the alternatives only. This results in the Easy subset with 190 instances and the Hard subset comprising the remaining 310 instances. You can download the Easy and Hard Subsets IDs here (6.4K)
Results
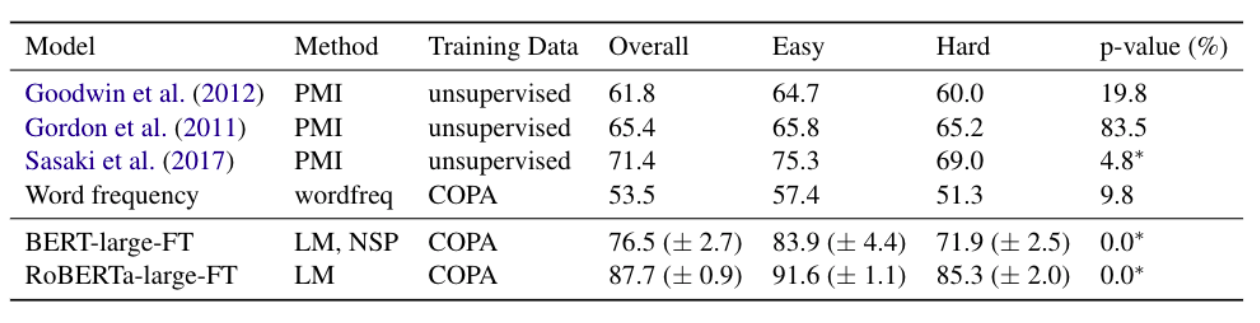
Evaluation on Easy and Hard Subsets
Prediction keys for BERT and RoBERTa are available Here predictions.tar.bz2 (2.2K)
Previous models perform similarly on both Easy and Hard subsets, with the exception of Sasakiet al. (2017). Overall both BERT and RoBERTa considerably outperform the best previous model. However, BERT’s improvements over previous work can be almost entirely attributed to high accuracy on the Easy subset: on this subset. This indicates that BERT relies on superficial cues. The difference between accuracy on Easy and Hard is less pronounced for RoBERTa, but still suggests some reliance on superficial cues. We speculate that superficial cues in the COPA training set prevented BERT and RoBERTa from focusing on task-related non-superficial cues such as causally related event pairs.
Effect of Balanced COPA
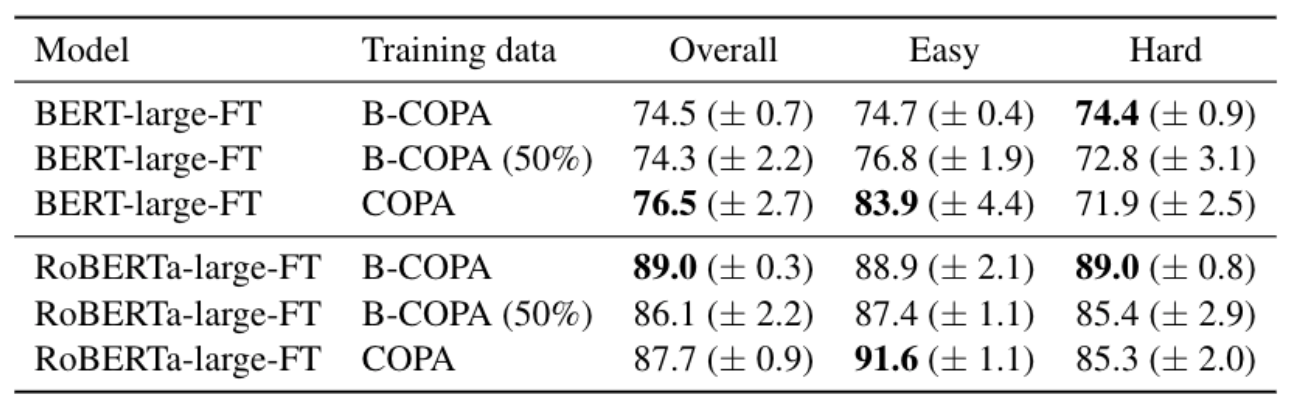
Once superficial cues are removed, the models are able to learn the task to a high degree.
The smaller performance gap between Easy and Hard subsets indicates that training on Balanced COPA encourages BERT and RoBERTa to rely less on superficial cues. Moreover, training on Balanced COPA improves performance on the Hard subset.
BERT/RoBERTa Sensitivity to Superficial Cues
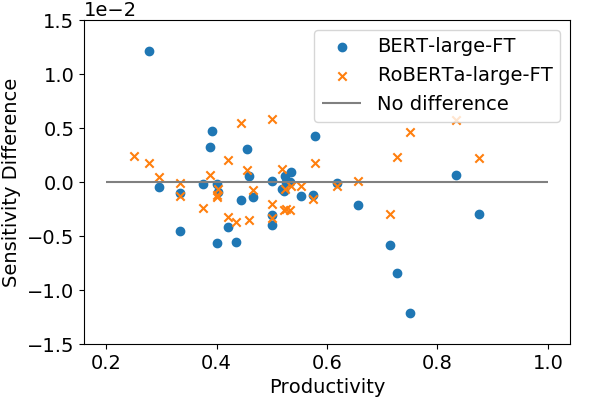
We observe that BERT trained on Balanced COPA is less sensitive to a few highly productive superficial cues than BERT trained on original COPA. Note the decrease in the sensitivity for cues of productivity from 0.7 to 0.9.
However, for cues with lower productivity, the picture is less clear, in case of RoBERTa, there are no noticeable trends in the change of sensitivity.
BERT Difference Embedding
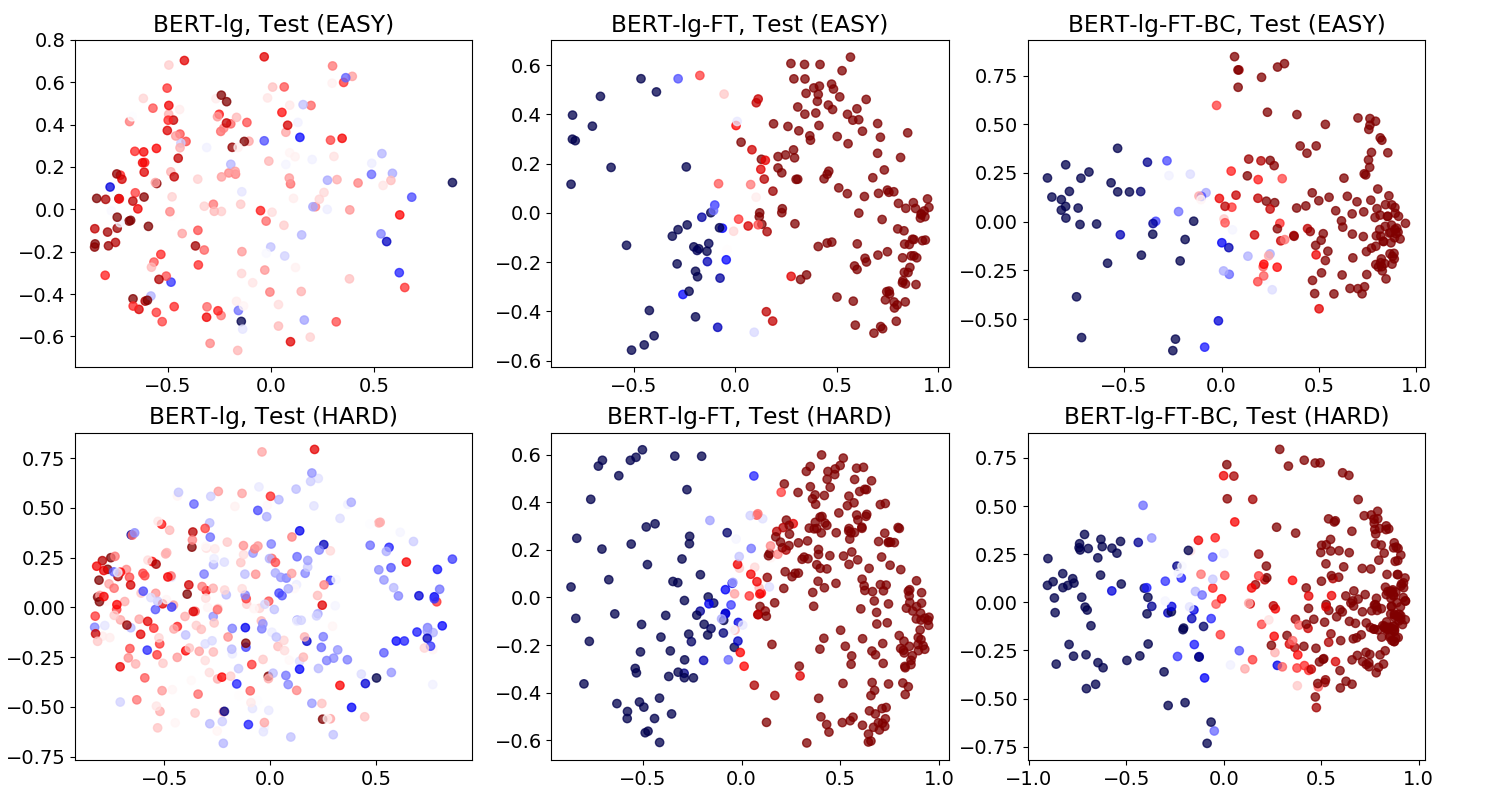
RoBERTa Difference Embedding